git db
decentralized data storage in git
The basic idea is taken from Google's Protocol Buffers. Columns are indexed by number, starting from 0. Each column in the row is introduced with a variable-length signed integer, encoded as per the Encoding rules, encoding the column number and the encoding type of the value which follows.
The lowest four bits of this number are interpreted as an enumerated type indicator for the value which follows; this is enough to scan the row into columns without a schema, though not enough to interpret the values fully.
The remaining top bits of the decoded integer indicate the column number. This is a relative number added to the next expected column. The number is relative to avoid two-byte sequences as much as possible, leave more room for type bits in the normal case and to hopefully improve compression ratios over absolute column numbering.
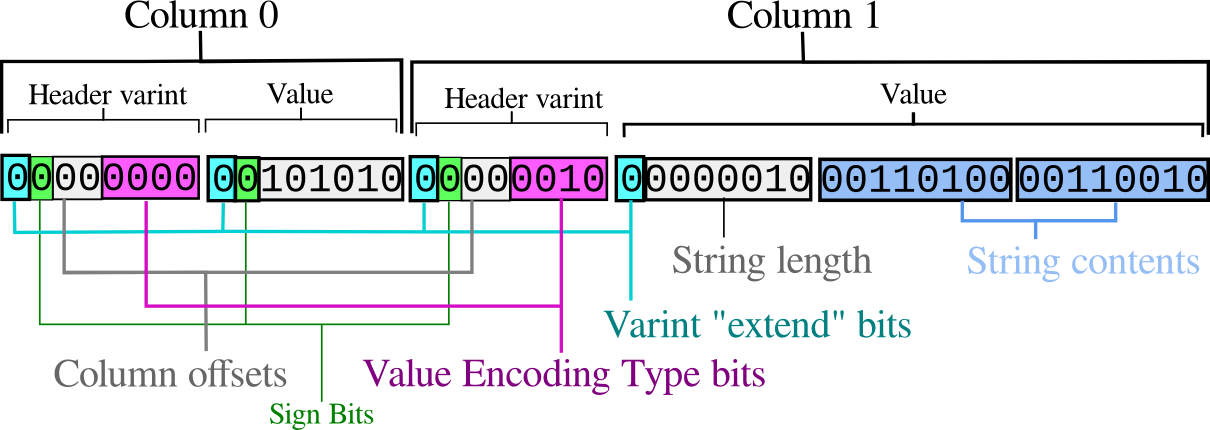
Figure 1. an example byte sequence, encoding (42, "42")
The column offset must be added to the next expected column. If this is '0' then it means that the column which appears is the next column. A number such as '2' means that there were two NULL columns (or columns dropped before this row was written) in between the last column read and this one.
A negative number means that the columns are appearing out of order; for example, the primary key was not set to the first defined columns in the original schema. These situations should be rare and hopefully may be excluded by some implementations and remain generally interoperable.
A completely different, more human readable encoding is used for converting primary key column values to filenames for referring to them. This is described in the next level, Filenames.
The meaning of the 4-bit type field is given below. Some of these come from ProtocolBuffer.
| type bits | ASCII | type name | description | follows | formulae (Numerics) |
|---|---|---|---|---|---|
| 0000 | ␀ | varint | Integer | varint N | N |
| 0001 | ␁ | float | Floating Point | varint E, M | M times 2^{E}& |
| 0010 | ␂ | string | Text or Binary data | varuint L, L bytes of data | - |
| 0011 | ␃ | decimal | Decimal Numbers | varint E, M | M times 10^{E} |
| 0100 | ␄ | rational | Rational Numbers (Fractions) | varint N, varuint D | M div D |
| 0101 | ␅ | false | Boolean (false) | none | - |
| 0110 | ␆ | true | Boolean (true) | none | - |
| 0111 | ␇ | lob | Large Object - oversized value | varuint L, L utf-8 bytes of filename | - |
| 1000 | ␈ | List<> | begin list of homogenous values | type T, varuint N, values V1..VN, pop | - |
| 1001 | ␉ | null | explicit/resetting NULL | none | - |
| 1010 | ␊ | eor | Row divider in row pages | none (next row) | - |
| 1011 | ␋ | rowleft | For fast scanning of pages by primary key | varuint L (bytes of rest of row, excluding eor) | - |
| 1100 | ␌ | - | reserved | - | - |
| 1101 | ␍ | reset | Reset column index to 0 (or offset) | - | - |
| 1110 | ␎ | Tuple<> | begin list of non-homogenous values | type T1, value V1, ... type Tx, value Vx, pop | - |
| 1111 | ␏ | pop | End list | previous context resumed | - |
The ASCII column reminds you what ASCII control character you will see if you end up directly inspecting heap contents (and the column offset is 0).

Figure 2. Encodings for true and false
There are two types assigned to booleans, effectively squeezing the value into the type code header.
Some standard types will have functions which decide on the appropriate encoding based on the value; booleans are one of them.
As in ProtocolBuffer, well formed rows from two sources can be merged by string concatenation, except using the ASCII carriage return (CR) character between them, which encodes a 'Reset' column. Normally it is not necessary to encode NULL column values; leaving them out is equivalent, but in the context of combining rows this may be useful. Explicit NULL values should never appear in stored rows or pages; it is reserved for stream use in situations where it is required.
Otherwise, a stream looks like a continuous data page; see the next section.
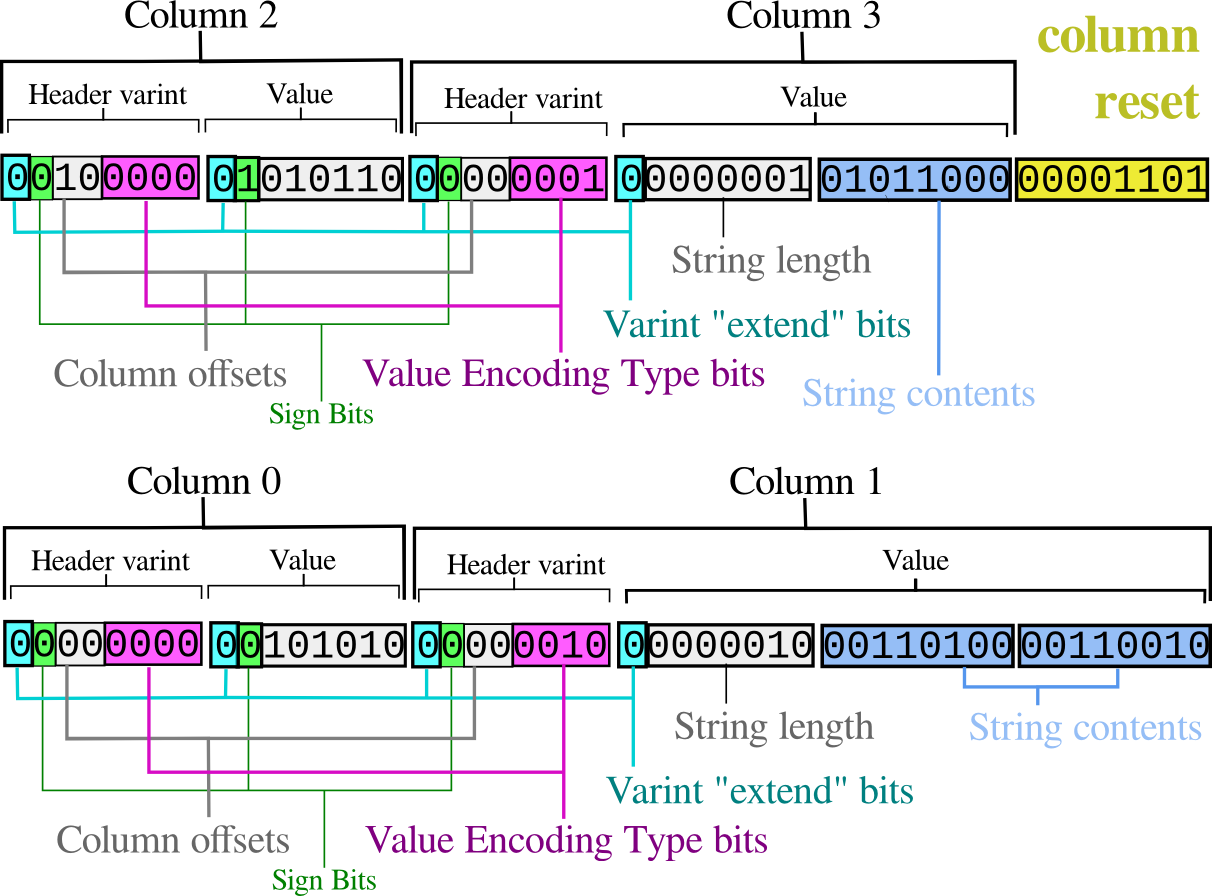
Figure 3. Column 2 and 3 can be sent before columns 0 and 1, by making the first emitted column have a column number of 2, following the extra columns with a column reset pseudo-type, and then the example from Figure 1, verbatim.
Two types are added for paged rows - blobs which contain multiple rows. Paging, as well as facilitating streaming, allows for "table compression" to work, useful for improving OLAP disk space use and scan requirements. Some implementations may find it appropriate to omit all support for row paging - it is described more in the TreeFormat section.
First, there is the eor marker, which allows for delimiting rows in a page.
Secondly, there is the rowleft type which appears after the primary key columns, to allow faster scanning by primary key in pages. Instead of decoding all columns on the way to the next row, the next primary key can be immediately located. The rowleft type encodes a varuint which is the length of the data columns in bytes; skipping that many bytes forward should land you on an eor marker.
For larger column values, they may have their data saved in their own blob instead of stored in the page using the 'string' code.
Postgres calls this feature "toast" tables. Some implementations will get away without implementing this.
The value of the column is a string, a filename. The filename is stored in the git tree, and a reference counting back-reference to the row (a la GiST index entry in Postgres) will be required to be able to effectively manage that.
While these concepts are not in every database (Postgres being the shining exception of course), it was clear during early development of this standard, and also from the design of projects such as Avro that this is actually a fairly fundamental feature. It's certainly fundamental in document store systems, which are sometimes limited to just arrays, hashes, strings and numbers yet still very useful.
Boolean encoding types are not permitted in these types in any use case where the column type byte may be omitted. Arrays of booleans can be represented as raw data blobs in the meantime.

Figure 4. the column contains a 17-member list of varint values.
With homogenous arrays, the values must all be of the same encoding type. The first varint to follow is a type specifier for the values, specified in exactly the same way as a column encoding; no offset should be specified. For a multi-dimensional array, this may specify the List<> type again. After the type comes a varuint, which is the number of values expected. The values appear directly afterwards.
The pop column specifier is to be found at the end of the list of values.
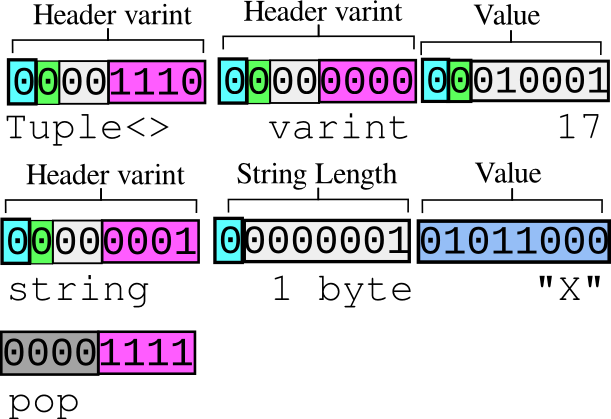
Figure 5. the column contains the tuple (17, "X")
Tuples are permitted where the type of a column is recorded as a record type in the store's meta columns (see MetaFormat). They are exactly the same thing as Postgres' compound types.
Whenever a tuple is used as a type, the Tuple<> introduction column type appears, followed by more columns (numbered beginning with column 0), followed by the pop column psuedo-type.
If the type of a list is Tuple<>, then a list of types is expected, terminated by a pop. If the list is empty, then each item in the array is a full (embedded) row, with each of its columns introduced with an encoding varint and a value, just like encoding a regular embedded Tuple. If however there is a list of types, then this defines the list for each item in the entire array, and just the values can be listed. This precludes individual items in the array having NULL values.
For example, an array of (string, float) - able to encode a map from string keys to floating point values - can be encoded as:
List<> Tuple<> string float pop N K1 V1 ... KN VN pop
This represents a complete overhead of as few as 7 bytes for the map, with values encoded as directly as can be after that.
If the tuples are not homogenous, then the list of types can be empty. One example of this is that some rows contain NULL for some data. Another is that row data is directly transferred from another source in this column without re-parsing.
List<> Tuple<> pop N
string K1 float V1 eor
string K2 float V2 eor
string KN float VN pop
Like with hetereogenous tuples above, passing no type to List allows for a different encoding, where no types are assumed, and each value in the array requires a type bit. The result is a tuple, which is filled into the list which defines the value, by column number.
For instance, to encode this list:
(42, 31, 16, "hut!", null, [1,2,3])
You'd use:
List<> pop varint 42 varint 31 varint 16 string 4 "hut!" +1List<> varint 3 1 2 3 pop pop
The +1List<> in the above is the List<> type, with the column offset of "+1" to mean, skip one column, leaving the null.
This is the only way to encode lists/arrays with nulls; the other form assumes an even n-dimensional array with all values of a common encoding.
When columns are added, they get a new number, and, when they are deleted, the numbers are not re-used. This is done so that frequently, schema modifications do not require major changes to the table data.
Lazy schema change operations might not mop up all of the columns which no longer exist; cleaning this up is akin to a VACUUM operation.