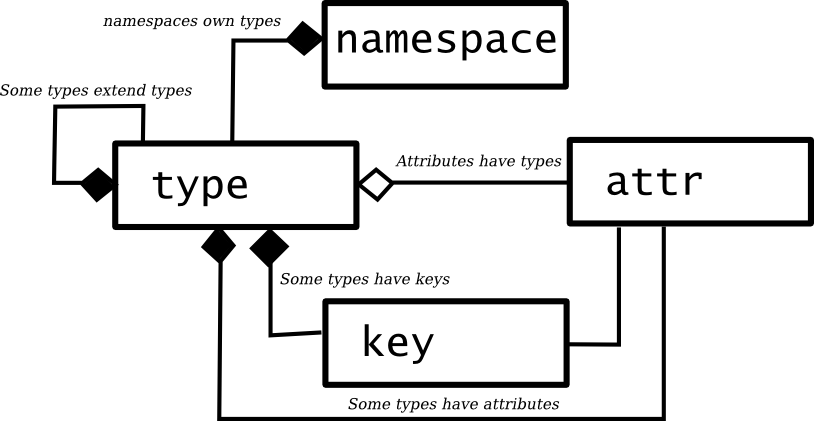
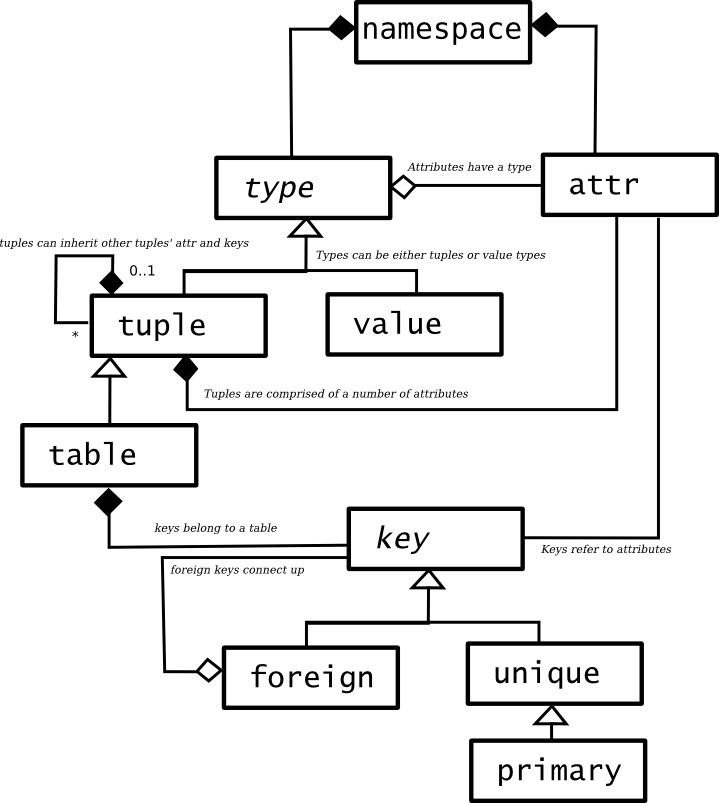
MetaFormat: specifying data structure
There is a special schema in the git db store which represents the
schema of the tables itself; these are identified with the meta.
schema name. Optionally there are rows in the schema which represent
the schema of the meta. store itself.
One way to understand how this works is to see how it works out with
a simple example schema.
The Namespace table (meta.namespace)
The namespace table is a local surrogate key given to the schema,
which is used as the first member of the primary key for all the other
types in the meta schema.
The namespace has a URL and revision pair. The URL is a
distinguishing feature of the schema. The revision number is
increased as the schema is modified going forward. The meta schema
itself can store multiple revisions of a single application's database
schema, under different names.
Here is a table describing the structure. The first four colums of
this table are equivalent to a query like:
select
attr_index, attr_name, attr_type, attr_required
from meta.attr
where ns_name = 'meta'
and type_name = 'namespace'
| attr_index |
attr_name |
attr_type |
attr_required |
Description |
Key(s) |
|---|
| 0 |
ns_name |
string |
yes |
local schema name |
Primary |
| 1 |
ns_url |
string |
yes |
uniquely identitying URL (may be empty) |
Unique (with ns_rev) |
| 2 |
ns_rev |
num |
yes |
schema iteration number |
Unique (with ns_rev) |
If you are storing in a verbose encoding such as JSON, then the
attribute indices are not important and property names are used
instead. For example, the meta schema could be declared with this
entry in /meta/namespace.json (or /meta/namespace/meta.json):
{ "ns_name": "meta",
"ns_url": "http://github.com/samv/Git-DB",
"ns_rev": 0.1,
}
It could also be encoded in binary as:
00000000 0204 6d65 7461 021d 6874 7470 3a2f 2f67 ␂␄meta␂␝http://g
00000010 6974 6875 622e 636f 6d2f 7361 6d76 2f47 ithub.com/samv/Gi
00000020 6974 2d44 4203 7f01 t-DB␃␡␁
This shows a curious situation, in that it is possible to include
information in the meta tables about the meta schema itself.
This is a well-known chicken-and-egg situation, found in type theory,
metaprogramming, etc.
To keep things simple when connecting, all that is required is a
single row which includes the meta schema URL and revision - and
if the implementation does not know how what that means, it cannot
process the rest of the schema metadata, and therefore should not
continue. If the data is provided, then it should be compared against
the known good data, and any discrepancies treated as a fatal error.
Types (meta.type)
Types are abstract, in that you can't just have a type, it has to be a
particular kind of type. When reading the row, which kind of type you
have can be distinguished from which attributes it posesses.
The type tuple exists only to keep a registry of type names within
a namespace. The primary namespace for types is their names and not a
surrogate index, which makes type renaming more complex, but makes the
schema overall nicer to work with. Numbered surrogates are used for
the attr table, only, as they are necessary for the binary column
format.
| Column |
Type |
Nullable |
Key(s) |
|---|
| ns_name |
string |
no |
Primary (with type_name) and Foreign to namespace |
| type_name |
string |
no |
Primary (with ns_name) |
Constraints and Keys
There are three types of indexes: primary keys, unique keys, and
foreign keys. These are all specializations of the 'key' tuple:
Summary
The schema so far is capable of storing typed and untyped data, as
well as achieving several of the various levels of normal form. An
important test is that the schema completely describes itself, and
naturally fits within itself.